from __future__ import absolute_import from __future__ import division from __future__ import print_function
import time
import matplotlib.pyplot as plt import numpy as np import tensorflow as tf from tensorflow import keras from tensorflow.keras import layers
from tensorflow_graphics.geometry.transformation import quaternion from tensorflow_graphics.math import vector from tensorflow_graphics.notebooks import threejs_visualization from tensorflow_graphics.notebooks.resources import tfg_simplified_logo
# Constructs the model. model = keras.Sequential() model.add(layers.Flatten(input_shape=(num_vertices, 3))) model.add(layers.Dense(64, activation=tf.nn.tanh)) model.add(layers.Dense(64, activation=tf.nn.relu)) model.add(layers.Dense(7))
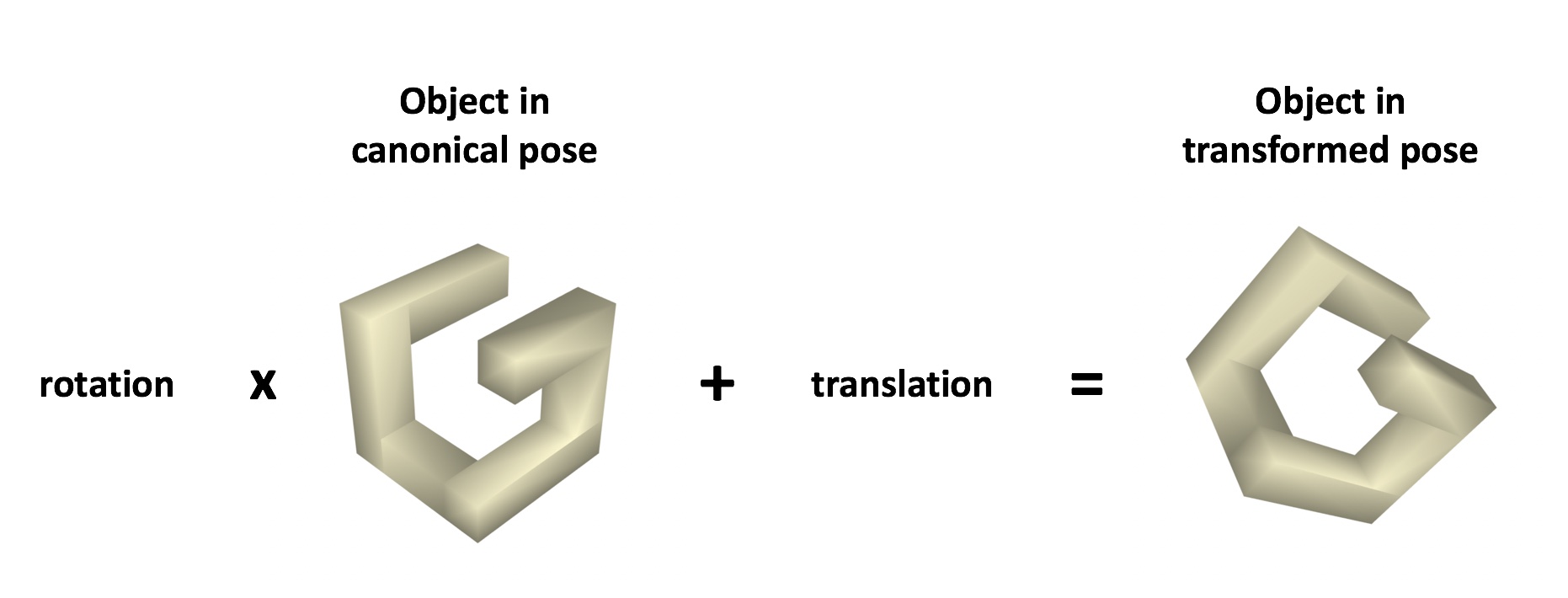
defpose_estimation_loss(y_true, y_pred): """Pose estimation loss used for training. This loss measures the average of squared distance between some vertices of the mesh in 'rest pose' and the transformed mesh to which the predicted inverse pose is applied. Comparing this loss with a regular L2 loss on the quaternion and translation values is left as exercise to the interested reader. Args: y_true: The ground-truth value. y_pred: The prediction we want to evaluate the loss for. Returns: A scalar value containing the loss described in the description above. """ # y_true.shape : (batch, 7) y_true_q, y_true_t = tf.split(y_true, (4, 3), axis=-1) # y_pred.shape : (batch, 7) y_pred_q, y_pred_t = tf.split(y_pred, (4, 3), axis=-1)
# transformed_corners.shape: (num_vertices, batch, 3) # q and t shapes get pre-pre-padded with 1's following standard broadcast rules. transformed_corners = quaternion.rotate(corners, y_pred_q) + y_pred_t
# google internal 1 # Everything is now in place to train. EPOCHS = 100 pt = ProgressTracker(EPOCHS) history = model.fit( data, target, epochs=EPOCHS, validation_split=0.2, verbose=0, batch_size=32, callbacks=[reduce_lr_callback, pt])
# Defines the loss function to be optimized. deftransform_points(target_points, quaternion_variable, translation_variable): return quaternion.rotate(target_points, quaternion_variable) + translation_variable
defget_random_transform(): # Forms a random translation with tf.name_scope('translation_variable'): random_translation = tf.Variable( np.random.uniform(-2.0, 2.0, (3,)), dtype=tf.float32)
# Forms a random quaternion hi = np.pi lo = -hi random_angles = np.random.uniform(lo, hi, (3,)).astype(np.float32) with tf.name_scope('rotation_variable'): random_quaternion = tf.Variable(quaternion.from_euler(random_angles))
Here the problem is tackled using mathematical optimization, which is another traditional way to approach the problem of object pose estimation. Given correspondences between the object in ‘rest pose’ (pastel lemon color) and its rotated and translated counter part (pastel honeydew color), the problem can be formulated as a minimization problem. The loss function can for instance be defined as the sum of Euclidean distances between the corresponding points using the current estimate of the rotation and translation of the transformed object. One can then compute the derivative of the rotation and translation parameters with respect to this loss function, and follow the gradient direction until convergence. The following cell closely follows that procedure, and uses gradient descent to align the two objects. It is worth noting that although the results are good, there are more efficient ways to solve this specific problem. The interested reader is referred to the Kabsch algorithm for further details.
Note: press play multiple times to sample different test cases.