原文标题:Rapid 3D Reconstruction for Image Sequence Acquired from UAV Camera
首发于:MDPI
Yufu Qu *, Jianyu Huang and Xuan Zhang
Department of Measurement Technology & Instrument, School of Instrumentation Science & Optoelectronics
Engineering, Beihang University, Beijing 100191, China; Hjy448@buaa.edu.cn (J.H.);
zhangxuanaj@buaa.edu.cn (X.Z.)Correspondence: qyf@buaa.eud.cn; Tel.: +86-010-8231-7336
Received: 23 November 2017; Accepted: 11 January 2018; Published: 14 January 2018
摘要
1 | In order to reconstruct three-dimensional (3D) structures from an image sequence captured by unmanned aerial vehicles’ camera (UAVs) and improve the processing speed, we propose a rapid 3D reconstruction method that is based on an image queue, considering the continuity and relevance of UAV camera images. |
为了加快无人机相机采集图像三维重建过程,我们提出了一种基于图像序列相关度的快速重建方法。
1 | The proposed approach first compresses the feature points of each image into three principal component points by using the principal component analysis method. In order to select the key images suitable for 3D reconstruction, the principal component points are used to estimate the interrelationships between images. |
该方法首先利用主成分分析法(Principal Components Analysis, PCA)将每幅图像的特征点压缩为 3 个主成分点。利用主成分点估计图像之间的相互关系,可以为选择适合三维重建的关键帧提供依据。
1 | Second, these key images are inserted into a fixed-length image queue. The positions and orientations of the images are calculated, and the 3D coordinates of the feature points are estimated using weighted bundle adjustment. With this structural information, the depth maps of these images can be calculated. |
其次,将这些关键帧插入到一个固定长度的图像队列中。计算图像的位置和方向,并使用加权束平差(weighted bundle adjustment)估计特征点的三维坐标。利用这些结构信息,可以计算出这些图像的深度图。
1 | Next, we update the image queue by deleting some of the old images and inserting some new images into the queue, and a structural calculation of all the images can be performed by repeating the previous steps. |
接着通过删除一些旧图像和插入一些新图像来更新图像队列,并重复前面的步骤对所有图像进行结构化计算。
1 | Finally, a dense 3D point cloud can be obtained using the depth–map fusion method. The experimental results indicate that when the texture of the images is complex and the number of images exceeds 100, the proposed method can improve the calculation speed by more than a factor of four with almost no loss of precision. |
最后利用深度图融合方法得到密集的三维点云。实验结果表明,当图像的纹理复杂且图像数量超过 100 时,该方法可以将计算速度提高 4 倍以上,几乎不损失精度。
1 | Furthermore, as the number of images increases, the improvement in the calculation speed will become more noticeable. |
此外,随着图像数量的增加,相较原方法计算速度也会明显地提高。
Keywords: UAV camera; multi-view stereo; structure from motion; 3D reconstruction; point cloud
1. Introduction 概述
1 | Because of the rapid development of the unmanned aerial vehicle (UAV) industry in recent years, civil UAVs have been used in agriculture, energy, environment, public safety, infrastructure, and other fields. By carrying a digital camera on a UAV, two-dimensional (2D) images can be obtained. However, as the requirements have grown and matured, 2D images have not been able to meet the requirements of many applications such as three-dimensional (3D) terrain and scene understanding. |
由于近年来无人机产业飞速发展,民用无人机已经能被应用于农业、能源、环境、公共安全、基础设施等领域。而无人机所携带的数字摄像头也能摄取 2D 图像。然而,随着需求的增长和成熟,2D 图像已经不能满足对三维场景和地形理解等多种应用的需求。
1 | Thus, there is an urgent need to reconstruct 3D structures from the 2D images collected from UAV camera. The study of the methods in which 3D structures are generated by 2D images is an important branch of computer vision. In this field, many researchers have proposed several methods and theories [1–17]. |
因此,从无人机摄像机采集的二维图像中重建三维结构成为了当务之急。利用二维图像生成三维结构的方法研究是计算机视觉的一个重要分支。在这一领域,许多研究者提出了几种方法和理论[1-17]。在这些理论和方法中,有三个最重要的类别,分别是 SLAM[1-3] ,SfM[4-14] 和 MVS[15-17] ,这些算法已经在许多实际应用中得到了实现。
1 | As the number of images and their resolution increase, the computational times of the algorithms will increase significantly, limiting them in some high-speed reconstruction applications. |
而随着图像数量和分辨率的增加,算法需要的时间显著增加,这极大地限制了一些需要高速三维重建的应用。
1 | Two major contributions in this paper are methods of selecting key images selection and SfM calculation of sequence images. Key images selection is very important to the success of 3D reconstruction. |
本文主要研究了序列图像中关键帧的选取方法和序列图像的 SfM 计算方法。关键帧的选择对于三维重建的成功至关重要。
1 | In this paper, a fully automatic approach to key frames extraction without initial pose information is proposed. Principal Component Analysis (PCA) is used to analyze the correlation of features over frames to automate the key frame selection. |
本文提出了一种无初始位姿信息的全自动关键帧提取方法。主成分分析法用于分析帧间特征之间的相关性,从而实现自动化的关键帧选择。
1 | Considering the continuity of the images taken by UAV camera, this paper proposes a 3D reconstruction method based on an image queue. To ensure the smooth of two consecutive point cloud, an improved bundle-adjustment named weighted is used in this paper. |
考虑到无人机摄像机拍摄图像的连续性,提出一种基于图像队列的三维重建方法。为了保证连续两个点云的平滑,本文采用了一种改进的光束法平差(BA)方法——加权光束法平差(WBA)。
1 | After using a fixed-size image queue, the global structure calculation is divided into several local structure calculations, thus improving the speed of the algorithm with almost no loss of accuracy. |
通过使用固定大小的图像队列,将全局结构计算分解为若干个子结构计算,从而提高了算法的速度,几乎不损失精度。
2. Literature Review 相关工作
1 | The general 3D reconstruction algorithm without a priori positions and orientation information can be roughly divided into two steps. |
一般的无先验位置和方向信息的三维重建算法大致可分为两步。
1 | The first step involves recovering the 3D structure of the scene and the camera motion from the images. The problem addressed in this step is generally referred to as the SfM problem. |
第一步是从图像中恢复场景的三维结构和摄像机的运动。这个步骤中涉及的问题通常称为 SfM 问题。
1 | The second step involves obtaining the 3D topography of the scene captured by the images. This step is usually completed by generating a dense point data cloud or mesh data cloud from multiple images. The problem addressed in this step is generally referred to as the MVS problem. |
第二步是获得由图像捕获的场景的三维地形图。这一步通常通过从多幅图像生成一个密集点数据云或网格数据云来完成。此步骤中涉及的问题通常称为 MVS 问题。
1 | In addition, the research into Real-time simultaneous localization and mapping (SLAM) and 3D reconstruction of the environment have become popular over the past few years. Positions and orientations of monocular camera and sparse point map can be obtained from the images by using SLAM algorithm. |
此外,在过去的几年中,实时即时定位与地图构建重建(SLAM)和环境三维重建的研究已经变得非常流行。利用 SLAM 算法可以从图像中获得单目相机和稀疏点地图的位置和方向。
2.1. SfM
1 | The SfM algorithm is used to obtain the structure of the 3D scene and the camera motion from the images of stationary objects. There are many similarities between SLAM and SfM. They both estimate the localizations and orientations of camera and sparse features. Nonlinear optimization is widely used in SLAM and SfM algorithms. |
利用 SfM 算法可以从静止物体的图像中获取三维场景的结构和摄像机的运动。SLAM 和 SfM 有许多相似之处,即都给出了相机位置、方向与稀疏特征的估计。非线性优化也在 SLAM 和 SfM 算法中有着广泛的应用。
1 | Researchers have proposed improved algorithms for different situations based on early SfM algorithms [4–6]. A variety of SfM strategies have emerged, including incremental [7,8], hierarchical [9], and global [10–12] approaches. Among these methods, a very typical one was proposed by Snavely [13], who used it in the 3D reconstruction of real-world objects. With the help of feature point matching, bundle adjustment, and other technologies, Snavely completed the 3D reconstruction of objects by using images of famous landmarks and cities. |
学者们基于早期 SfM 算法[4-6]提出了针对不同情况的改进算法,演化出各种 SfM 策略,包括渐进式[7,8]、分层式[9]和全局式[10-12]方法。在这些方法中,Snavely 提出了一种非常典型的方法[13],并将其用于真实物体的三维重建:借助于特征点匹配、光束法平差等技术,并成功利用著名地标和城市的图像完成了重建。
1 | The SfM algorithm is limited in many applications because of the time-consuming calculation. With the continuous development of computer hardware, multicore technologies, and GPU technologies, the SfM algorithm can now be used in several areas. There are several improved SfM methods such as the method proposed by Wu [8 , 14]. These methods can improve the speed of the structure calculation without loss of accuracy. |
SfM 算法由于计算时间较长,在许多应用中受到限制。但随着计算机硬件、多线程技术和 GPU 技术的不断发展,SfM 算法已经可以应用于多个领域。现阶段有不少 SfM 方法的改进,例如 Wu 提出的方法[8,14]。这些方法在不损失精度的前提下,提高了结构计算的速度。
1 | Among the incremental SfM, hierarchical SfM, and global SfM, the incremental SfM is the most popular strategy for the reconstruction of unordered images. Two important steps in incremental SfM are the feature point matching between images, and bundle adjustment. As the resolution and number of images increase, the number of matching points and parameters optimized by bundle adjustment will increase dramatically. This results in a significant increase in the computational complexity of the algorithm and will make it difficult to use it in many applications. |
在前文提及的渐进式 SfM(又称增量 SfM)、层次式 SfM 和全局式 SfM 中,渐进式 SfM 是最常用的无序图像重建策略,其两个重要步骤是图像和光束法平差之间的特征点匹配。随着图像的分辨率和数量的增加,匹配点的数量和参数的优化光束法平差将大幅度增加,而这会导致该算法的计算复杂度显著增加,故难以在许多应用中使用。
2.2. MVS
1 | When the positions and orientations of the cameras are known, the MVS algorithm can reconstruct the 3D structure of a scene by using multiple-view images. |
当摄像机的位置和方向已知时,MVS 算法可以利用多视点图像重建场景的三维结构。
1 | One of the most representative methods was proposed by Furukawa [15]. This method estimates the 3D coordinates of the initial points by matching the difference of Gaussians and Harris corner points between different images, followed by patch expansion, point filtering, and other processing. The patch-based matching method is used to match other pixels between images. After that, a dense point data cloud and mesh data cloud can be obtained. |
最有代表性的方法之一是ふるかわ提出的多视点立体图构建[15]:通过匹配不同图像之间的高斯差(Difference of Gaussians)和哈里斯角点(Harris Corner Points)来估计初始点的三维坐标,接着进行分块展开、点滤波等其他处理,并采用基于分块的方法对图像中的其他像素进行匹配,即能得到密集点云与网格模型。
1 | Inspired by Furukawa’s method, some researchers have proposed several 3D reconstruction algorithms [16-18] based on depth-map fusion. These algorithms can obtain reconstruction results with an even higher density and accuracy. The method proposed by Shen [16] is one of the most representative approaches. The important difference between this method and Furukawa’s method is that it uses the position and orientation information of the cameras as well as the coordinates of the sparse feature points generated from the structure calculation. The estimated depth maps are obtained from the mesh data generated by the sparse feature points. Then, after depth–map refinement and depth–map fusion, a dense 3D point data cloud can be obtained. An implementation of this method can be found in the open-source software openMVS [16]. |
受ふるかわ方法的启发,一些学者提出了几种基于深度图融合的三维重建算法[16-18],可以以更高的密度和精度获得重建结果。其中 Shen 提出的方法[16]是最有代表性的方法之一。该方法与ふるかわ的方法的区别在于,它既利用了摄像机的位置、方向,同时考虑了计算生成的稀疏特征点的坐标。其方法通过稀疏特征点生成的网格数据,计算出一个深度图。接着进行深度图细化(refinement)和融合(fusion),就能得到一个密集的三维点云。另外,开源项目 openMVS 为该方法的一个实现。
1 | Furukawa’s approach relies heavily on the texture of the images. |
ふるかわ的方法十分依赖图像的纹理精度。在处理纹理模糊的图像时,这种方法很难生成密集点云。此外,该算法还需要多次进行补片扩展和点云滤波,从而大大增加了计算时间。与ふるかわ的方法相比,Shen 的方法使用深度图融合直接生成密集点云,且更加方便、快速。考虑到该研究中的问题特点,我们使用了一种类似于 Shen 的方法来生成一个密集点云。
2.3. SLAM
1 | SLAM mainly consists in the simultaneous estimation of the localization of the robot and the map of the environment. The map obtained by SLAM is often required to support other tasks. The popularity of SLAM is connected with the need for indoor applications of mobile robotics. As the UAV industry rises, SLAM algorithms are widely used in UAV applications. |
SLAM,即同步定位与地图构建,被许多应用任务依赖,其热度与很多室内机器人的研究有关。而随着无人机产业的兴起,SLAM 更是得到了广泛的关注与应用。
1 | Early SLAM approaches are based on Extended Kalman Filters, Rao-Blackwellised Particle Filters, and maximum likelihood estimation. Without priors, MAP estimation reduces to maximum-likelihood estimation. |
早期的 SLAM 方法基于扩展卡尔曼滤波(Extended Kalman Filters)、 Rao-Blackwellised 粒子滤波(Rao-Blackwellised Particle Filters)和最大似然估计(maximum likelihood estimation)。在没有先验信息的情况下,MAP 估计(MAP estimation)退化为最大似然估计。
1 | Most SLAM algorithms are based on iterative nonlinear optimization [1,2]. The biggest problem of SLAM is that some algorithms are easily converging to a local minimum. It usually returns a completely wrong estimate. Convex relaxation is proposed by some authors to avoid convergence to local minima. These contributions include the work of Liu et al. [3]. Kinds of improved SLAM algorithms have been proposed to adapt to different applications. Some of them are used for vision-based navigation and mapping. |
大多数 SLAM 算法是基于迭代非线性优化[1,2],然而其最大问题是部分算法很容易收敛至局部极小值,从而导致一个完全错误的结果。为了避免收敛到局部极小值,一些学者提出了凸松弛法(Convex relaxation),例如 Liu et al. 的研究[3],针对不同的应用场合,提出了多种改进的 SLAM 算法,其部分算法也能够用于基于视觉的导航和地图绘制。
3. Method 方法
3.1. Algorithm Principles 算法流程
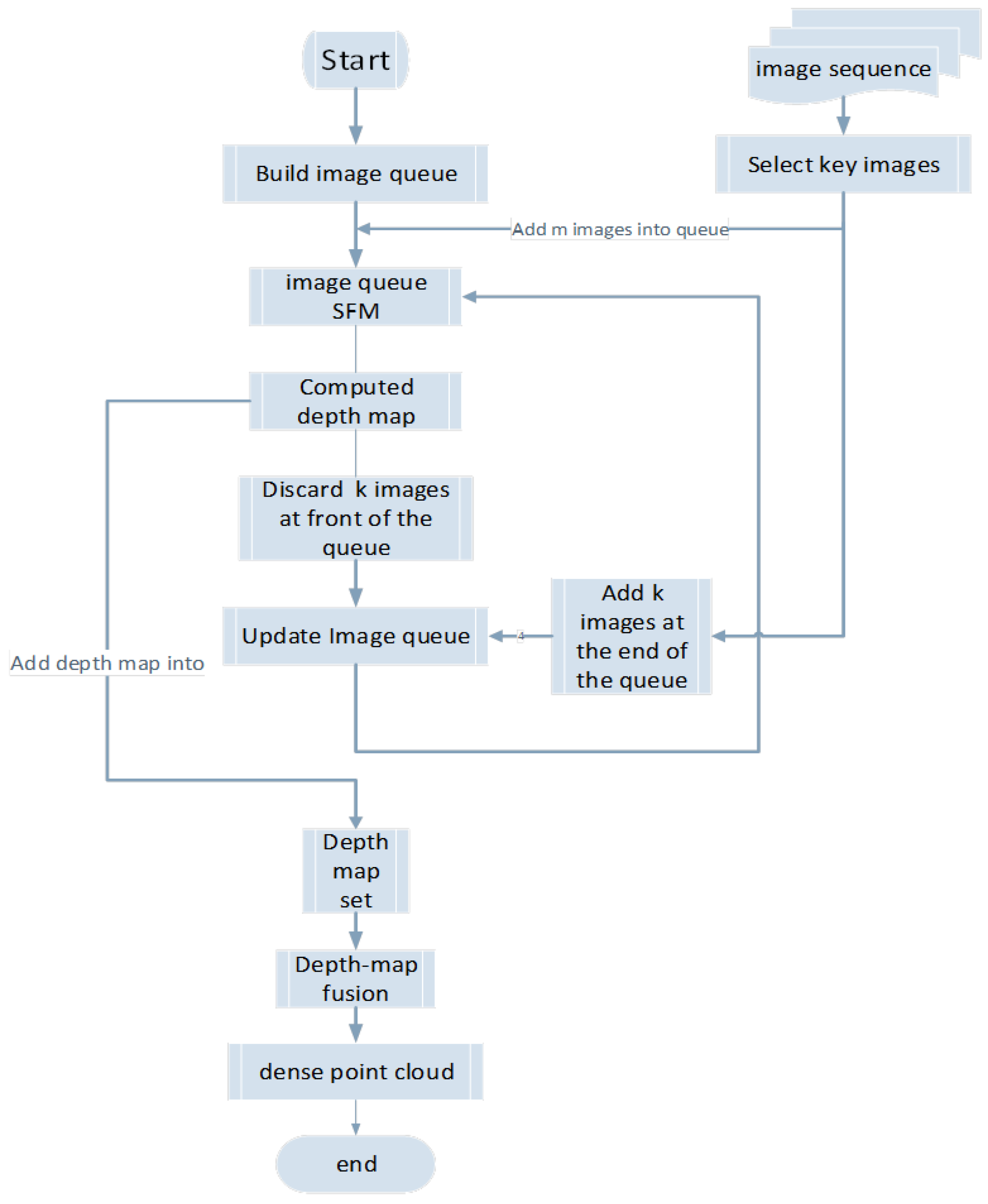
1 | The first step of our method involves building a fixed-length image queue, selecting the key images from the video image sequence, and inserting them into the image queue until full. A structural calculation is then performed for the images of the queue. Next, the image queue is updated, several images are deleted from the front of the queue, and the same number of images is placed at the end of the queue. The structural calculation of the images in the queue is then repeated until all images are processed. On an independent thread, the depth maps of the images are calculated and saved in the depth-map set. Finally, all depth maps are fused to generate dense 3D point cloud data. Without the use of ground control points, the result of our method lost the accurate scale of the model. The algorithm flowchart is outlined in Figure 1. |
第一步构建一个固定长度的帧队列,从视频帧序列中选择关键帧,并将它们插入到帧队列中直到上限。然后对队列的所有帧进行结构计算。接着更新图像队列:删除队列前面的几个图像,并在队列末尾放置相同数量的图像。然后重复队列中图像的结构计算,直到处理完所有图像。构建一个独立线程,来计算图像的深度图并将其保存在深度图集中。最后,将所有深度图融合生成密集的三维点据。由于没有使用地面控制点,方法得到的模型比例不准确。算法流程图如图 1 所示。
3.2. Selecting Key Images 筛取关键图像
1 | In order to complete the dense reconstruction of the point cloud and improve the computational speed, the key images (which are suitable for the structural calculation) must first be selected from a large number of UAV video images captured by a camera. |
为了完成密集点云的重建并提高计算速度,首先需要从无人机摄像头采集的大量视频图像中选取适合结构计算的关键帧,选取的关键帧之间应具有明显的场景重叠区域。
1 | For two consecutive key images, they must meet the key image constraint (denoted as R (I_1, I_2 )) if they have a sufficient overlap area. In this study, we propose a method for directly selecting key images for reconstructing the UAV camera’s images (the GPS equipped on the UAV can only reach an accuracy on the order of meters; by using GPS information as a reference for the selection of key images, discontinuous images will form). |
对于两个连续的关键帧,如果它们有足够多的重叠区域,则必须满足关键帧约束,记为 R(I_1, I_2)。本文提出了一种直接选取关键帧重建无人机摄像图像的方法(无人机上装备的 GPS 只能达到米级的精度,利用 GPS 信息作为关键图像选取的参考,就会形成不连续的图像)。
1 | The overlap area between images can be estimated by the correspondence between the feature points of the images. In order to reduce the computational complexity of feature point matching, we propose a method of compressing the feature points based on principal component analysis (PCA). It is assumed that the images used for reconstruction are rich in texture. Three principal component points (PCPs) can be generated from PCA, each reflecting the distribution of the feature points in different images. If the two images are captured almost at the same position, the PCPs of them almost coincide in the same place. Otherwise, the PCPs will move and be located in different positions on the image. |
通过图像特征点之间的对应关系,可以估计图像之间的重叠区域。为了降低特征点匹配的计算复杂度,本文提出了一种基于主成分分析(PCA)的特征点压缩方法。假设用于重建的图像具有丰富的纹理信息,主成分分析法可以生成三个主成分点(PCPs),而每个主成分点反映不同图像中特征点的分布情况。如果两幅图像在同一位置拍摄的,那么它们的主成分点必然重合在同一个地方,否则不然。
1 | The process steps are as follows. First, we use the scale-invariant feature transform (SIFT) [19] feature detection algorithm to detect the feature points of each image (Figure 2a). There must be at least four feature points, and the centroid of these feature points can then be calculated as follows: |
筛取的详细步骤如下。第一步利用尺度不变特征变换(SIFT) [19] 来检测每张图像的特征点(图 2a),通过选取 4 个特征点,则它们的质心由下公式计算:
$$
\overline{P} = \frac{1}{n}\sum^n_{i=1}{P_i},
P_i=\left(\begin{array}{}x\y\end{array}\right)
$$
1 | where P_i is the pixel coordinate of the feature point, and -p is the centroid. The following matrix is formed by the image coordinates of the feature points: |
其中 P_i 为特征点的像素坐标,\overline{p} 为质心。则可以得到如下矩阵:
$$
A = \begin{bmatrix}
(P_1 - \overline P)^T\
\vdots \
(P_n - \overline P)^T\
\end{bmatrix}
$$
1 | Then, the singular value decomposition (SVD) of matrix A yields two principal component |
矩阵 A 的奇异值分解(SVD)可以得到 2 个主分量向量,利用公式 (3)、(4) 可以压缩大量特征点至三个主成分点(图 2b)。
$$
U\sum{V^*}=svd(A)
$$
$$
p_{m1}=\overline P, P_{m2} = (V_1 + \overline P),p_{m3} = (V_2 + \overline P)
$$
1 | where pm1, pm2, and pm3 are the three PCPs, and V 1 and V 2 are the two vectors of V*. The PCPs can reflect the distribution of the feature points in the image. After that, by calculating the positional relationship of the corresponding PCPs between two consecutive images, we can estimate the overlap area between images. |
其中p_{m1}、p_{m2}、p_{m3} 为三个主成分点,V_1 和 V_2 为 V^* 的两个向量。这些主成分点能够反映图像中特征点的分布情况。接着只需计算两幅连续帧之间相应的 PCP 位置关系,就能预测出帧之间的重叠区域。
1 | The average displacement ( d_p ) between PCPs, as expressed in Equation (5), can be calculated as follows: d p reflects the relative displacement of feature points; when d_p < D_l , it is likely that the two images are almost captured at the same position; and when d_p > D_h , the overlap area of two images becomes too small. In this paper, we use 1/100 of the resolution as the value of D_l and 1/10 of the resolution as the value of D_h. When d p is within the certain range given in Equation (6), the two images will meet the key image constraint R ( I_1 , I_2 ) |
如公式 (5) 所示,定义 d_p 为两帧 PCPs 的“距离”,反映特征点的相关度,并将 d_p 约束在两个阈值 D_l、D_h 之间。若 d_p < D_l,则可以认为两帧拍摄点重合(又言之十分接近);若 d_p > D_l,则可以认为两帧重合部分太少了。本文D_l 取 1/100,D_h 取 1/10,当满足公式 (6) 时,则称两帧满足关键帧约束 R(I_1, I_2)。
$$
d_p = \frac {1}{3} \sum^3_{i=1} {[(p_{1i}-p_{2i})^T\times (p_{1i}-p_{2i})]^{0.5}}
$$
$$
R(I_1,I_2):D_l<d_p<D_h
$$
1 | where p 1i is the ith PCP of the first image (I_1 ), and p 2i is that of the second image (I_2 ). The result is presented in Figure 2c. This is a method for estimating the overlap areas between images, and it is not necessary to calculate the actual correlation between the two images when selecting key images. Moreover, the algorithm is not time-consuming for either the calculation of the PCPs or the estimation of the distance between PCPs. Therefore, this method is suitable for quickly selecting key images from a UAV camera’s video image sequence. |
其中 p_1i 为前一帧(I_1)第 i 个 PCP, p_2i 为后一帧(I_2)第 i 个 PCP(结果如图 2c)。得益于这种估计图像重叠区域的方法,在选择关键图像时不需要计算两图像之间的实际相关性。此外,无论是计算 PCP 还是估计 PCP 之间的“距离”,该算法都不耗时,因此也适用于无人机飞行时实时选取。

3.3 Image Queue SfM 图像序列动态重建
1 | This study focuses on the 3D reconstruction of UAV camera’s images. Considering the continuity of UAV camera’s images, we propose a SfM calculation method based on an image queue. This method constructs a fixed-size image queue and places key images into the queue until full. Then, the structure of the images in the queue is computed, and the queue is updated with new images. Eventually, we will complete the structural calculation of all images by repeating the structural computation and queue update. The image queue SfM includes two steps. The first involves the SfM calculation of the images in the queue. The second involves updating the images in the image queue. |
本文主要研究无人机相机图像的三维重建问题,故考虑到无人机摄像图像的连续性,我们提出了一种基于图像队列的 SfM 计算方法。该方法构造了一个定长的帧队列,并将关键帧放入队列直至上限。然后计算队列中图像的重建结构,并用新图像更新队列。最后,通过不断重复结构计算和队列更新,完成所有图像的计算并给出一个完整模型。图像序列 SfM 方法包括两个部分:一是对帧队列进行 SfM 计算方法,二是帧队列图像更新策略。
3.3.1 SfM Calculation for the Images in the Queue
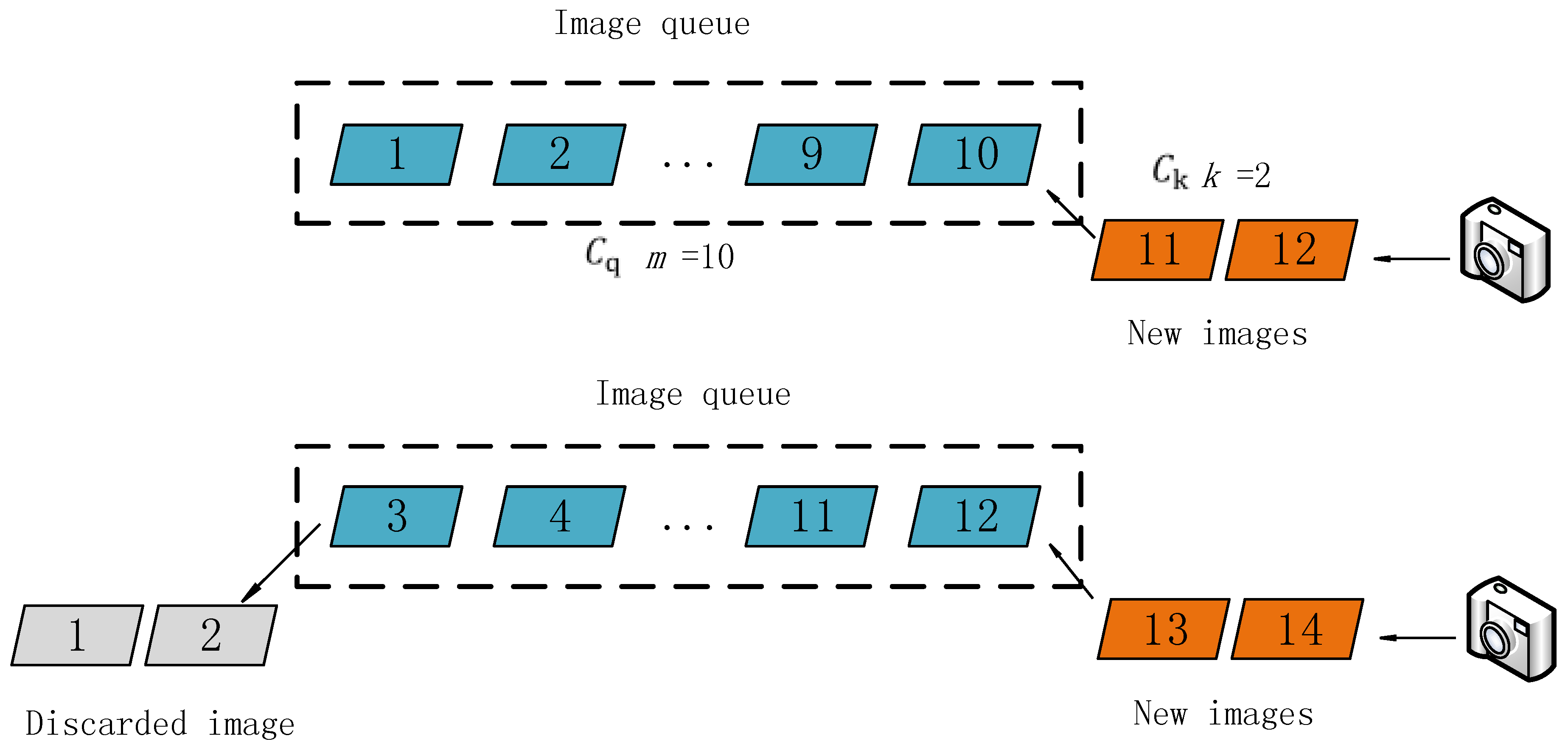
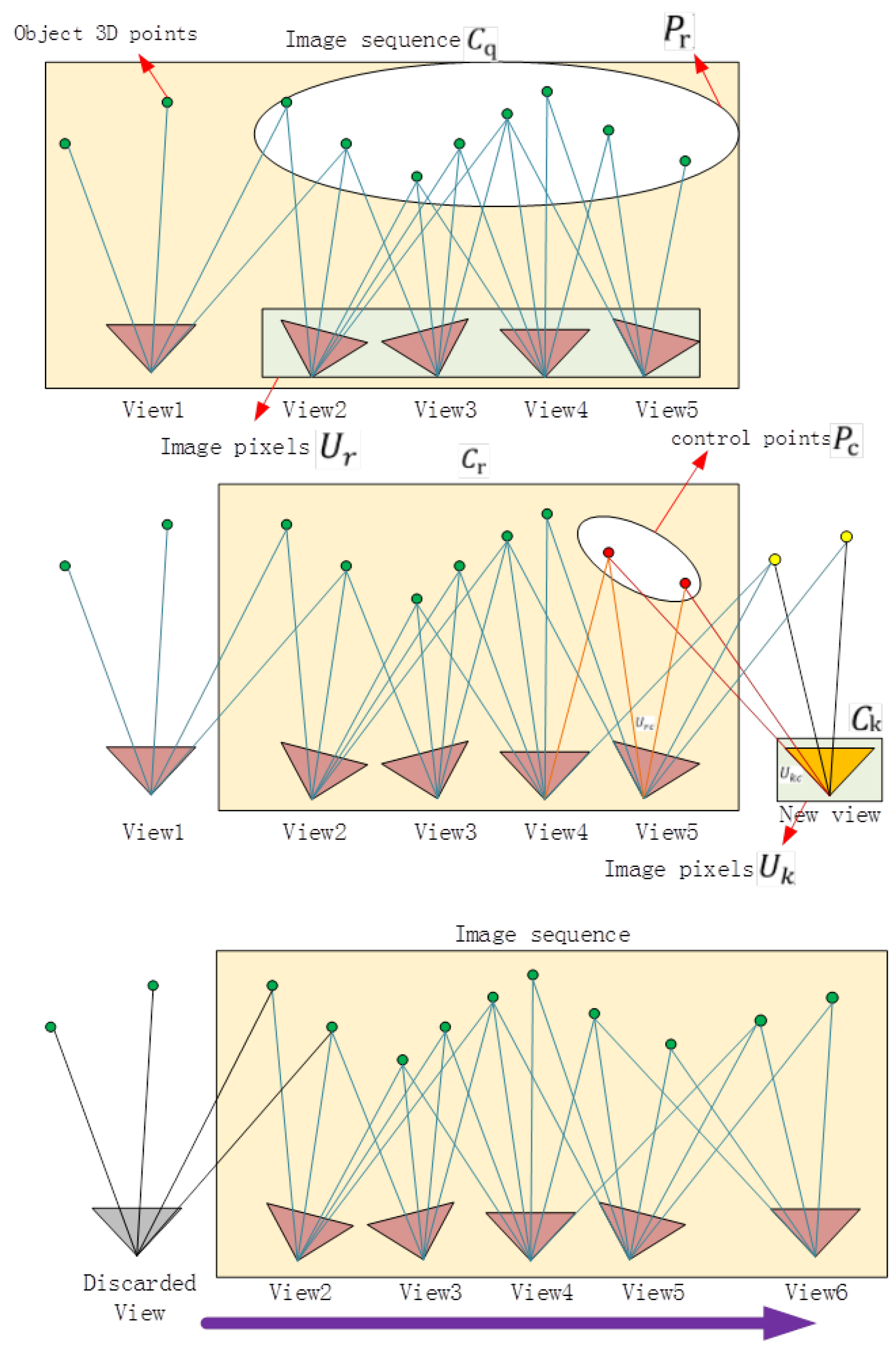
1 | We propose the use of the incremental SfM algorithm. The process is illustrated in Figure 3. The collection of all images used for the reconstruction is first recorded as set C. The total number of images in C is assumed to be N. The size of the initial fixed queue is m (it is preferred that any two images in the queue have overlapping areas, and m can be modified according to the requirements of the calculation speed. When m is chosen as a smaller number, the speed increases, but the precision decreases correspondingly). In order to keep the stability of the algorithm, the value of m is generally taken greater than 5, and k is less than half of m. Then, m key images are inserted into the image queue. All of the images in the image queue are recorded as C_q , and the structure of all of the images in C_q is calculated. |
本文使用渐进式 SfM 算法(图 3),首先将所有用于重建的图像记为集合 C,图像总数为 N。定义一个定长队列,长度为 m,队列中任意两幅图像都应当有重合区域。m 的取值将影响运算速度,取值越小,速度越快,精度相应降低。为了保证算法稳定,一般 m 取值大于 5,且 k < m/2。在队列中插入 m 张关键帧,记队列中的图集为 C_q,接着计算该队列中对应的结构。
1 | Considering the accuracy and speed of the algorithm, the SfM approach used in this study uses an incremental SfM algorithm [7]. The steps of the algorithm are summarized below. |
考虑到算法的准确性和速读,本研究中使用渐进式 SfM 算法[7],算法步骤如下。
1 | 1. The SIFT [19] feature detection algorithm is used to detect the feature points on all images in the queue, and the correspondence of the feature points are then obtained by the feature point matching [20] between every two images in the queue. |
- 使用 SIFT [19] 特征提取算法检测队列中所有图像的特征点,然后通过队列中每两幅图像之间的特征点匹配[20]获得特征点的对应关系。
- 采用文献 [21] 中的方法,从队列中选取两张作为初始图像对,通过随机抽样一致算法(RANSAC)来获取基础矩阵(fundamental matrix)。接着在相机内参矩阵(intrinsic matrix)已知([23] 校正方法)的情况,计算两帧间的本质矩阵(essential matrix)。此时,用于图像校正的径向、切向畸变参数的前两项也能求出,对像素进行重映射就能消除由镜头引起的畸变。然后对本质矩阵进行分解 [24] 就能得到图像对应的位置和方向。
- 根据特征点对应的关系,使用三角定位来获取该图像特征点的三维坐标(特征点标记为
P_i(i=1,…,t))。 - 对前面步骤计算出的参数采用光束平差法[25]进行非线性优化[26]。
- 计算出初始图像对所对应的结构,并选取一个图像的摄像机坐标作为全局坐标系原点。已完成计算的图像放入集合
C_SFM(C_SFM⊂C_q)。 - 向集合
C_SFM添加新图片I_new,并计算结构(译:怎么又计算?)。这张新图片需要满足以下两个条件:第一,在C_SFM需要至少有一张图片与I_new有共同的特征点;第二,这些共同特征点至少要有 6 个在P_i中(为了实验数据稳定,本研究定义需要 15 个共同特征点)。最后,再使用光束平差法优化计算出的结构参数。 - 重复第 6 步,直至队列中的所有图像计算完毕(
C_SFM=C_q)。
3.3.2. Updating the Image Queue 更新图像队列
1 | After the above steps, the structural calculation of all of the images in C_q can be performed. In order to improve the speed of the structural calculation of all of the images in C, this study proposes an improved SfM calculation method; the structural calculation of the images is processed in the form of an image queue. Figure 4 illustrates the process of the algorithm. We delete k images at the front of the queue, save their structural information, and then place k new images at the tail of the queue; these k images are then recorded as a set C_k. The (m − k) images left in the queue are recorded as a set C_r ( C_q = C_r ∪ C_k ), so now C_SFM = C_r. |
按上述步骤处理完 C_q 内所有图像后,需要更新该图像队列。采用图像队列这一方法,结合渐进式 SfM 算法,能有效提高重建计算速度。图 4 演示了该算法过程。
首先删除队列中前 k 个图像并保存它们的结构信息,然后在队列尾部追加 k 个新图像,记该 k 个图像的集合为 C_k,而原先留在队列中的 m-k 个图像集合记为 C_r(C_q=C_r∪C_k),因而现在 C_SFM=C_r。
1 | The structure of the images in C r is known, and the structural information contains the coordinates of the 3D feature points (marked as P_r ). |
目前,C_r对应的结构已知,且其特征点(记为 P_r)的三维坐标也已知。记特征点 P_r 对应的图像像素集合为U_r,其映射关系记为 P:P_r→U_r。然后检测新图像(C_k)中的特征像素(记为U_k),并匹配U_k与U_r。我们可以得到一个点对应关系 M:U_rc↔U_kc(U_rc∈U_r, U_kc∈U_k),分别对应相同的三维特征点P_c(也称控制点),将这个映射分别定义为P:P_c→U_kc, P_c→U_rc。
利用 P_c 和 U_kc 之间的投影关系,估计出 C_k 中图像的投影矩阵,从而计算出摄像机的位置和方向。另外,P_c 可以通过后文提及的加权光束法平差来确保结构的连续性。接着继续重复上节的第 6 步直至C_SFM=C_q。至此一轮图像更新完成,只需重复更新图像、队列计算就能得到所有图像的对应结构点云。
3.3.3. Weighted Bundle Adjustment 加权光束法平差
1 | An important part of the SfM algorithm is bundle adjustment. |
光束法平差是 SfM 算法的重要组成部分。我们的方法将大量图像以队列形式分割开来,这样容易使得光束法平差的优化结果陷入局部最优,继而导致全局不连续。
这个问题可以通过加入控制点来解决,即连接图像中两组相邻特征点的点(如图 5)。当我们使用光束法平差来优化参数时,我们要尽可能保持控制点不变,只允许微小变动。而这可以通过加入加权控制点的误差项来实现。在图像队列的第一次更新之后,我们需要对第6步中使用的光束法平差的投影误差公式进行重写。
1 | For a single image, Equation (7) is the projection formula of the 3D point to the image pixel, and Equation (8) is the reprojection error formula: |
对于单幅图像,公式(7)是三维点到图像像素的投影公式,公式(8)是重投影误差公式:
$$
\left(\begin{array}{}{v_i}^f\{u_i}^f\end{array}\right)
=K[R,t]\left(\begin{array}{}p_i\1\end{array}\right)
=f(R,T,P_i)
$$
$$
e_{project}=\sum^{n}_{i=1}{\left{\left(\left(\begin{array}{}v_i\u_i\end{array}\right)-\left(\begin{array}{}{v_i}^f\{u_i}^f\end{array}\right)\right)^T
\times\left(\left(\begin{array}{}v_i\u_i\end{array}\right)-\left(\begin{array}{}{v_i}^f\{u_i}^f\end{array}\right)\right)\right}}
$$
$$
e_{project}=\sum^{n}{i=1}{\left{\left(\left(\begin{array}{}v_i\u_i\end{array}\right)-\left(\begin{array}{}{v_i}^f\{u_i}^f\end{array}\right)\right)^T
\times\left(\left(\begin{array}{}v_i\u_i\end{array}\right)-\left(\begin{array}{}{v_i}^f\{u_i}^f\end{array}\right)\right)\right}}
\+w_j\sum^c{j=1}{\left{\left(\left(\begin{array}{}v_j\u_j\end{array}\right)-\left(\begin{array}{}{v_j}^f\{u_j}^f\end{array}\right)\right)^T
\times\left(\left(\begin{array}{}v_j\u_j\end{array}\right)-\left(\begin{array}{}{v_j}^f\{u_j}^f\end{array}\right)\right)\right}}
$$
1 | where K is the internal matrix of the camera, R and T are the external parameters, P i is the 3D feature point, (v_i,u_i)^T is the actual pixel coordinate of the feature point, and (v_i^f,u_i^f)^T is the pixel coordinate calculated from the structural parameters. The number of control points is k. The calculation of the bundle adjustment is a nonlinear least-squares problem. The structural parameters (R,T,P i ( i = 1,...,n )) can be optimized by minimizing e projrct after changing the value of the parameters. |
其中 K 为相机内参矩阵,R和T是外参矩阵,P_i 是立体特征点,(v_i,u_i)^T 是特征点的实际像素坐标,(v_i^f\\u_i^f)^T 是根据结构参数计算出来的像素坐标。共有 k 个控制点。光束法平差的计算是一个非线性最小二乘问题。结构参数 (R,T,P_i) 则需要通过最小化 e_project 来取得最优。
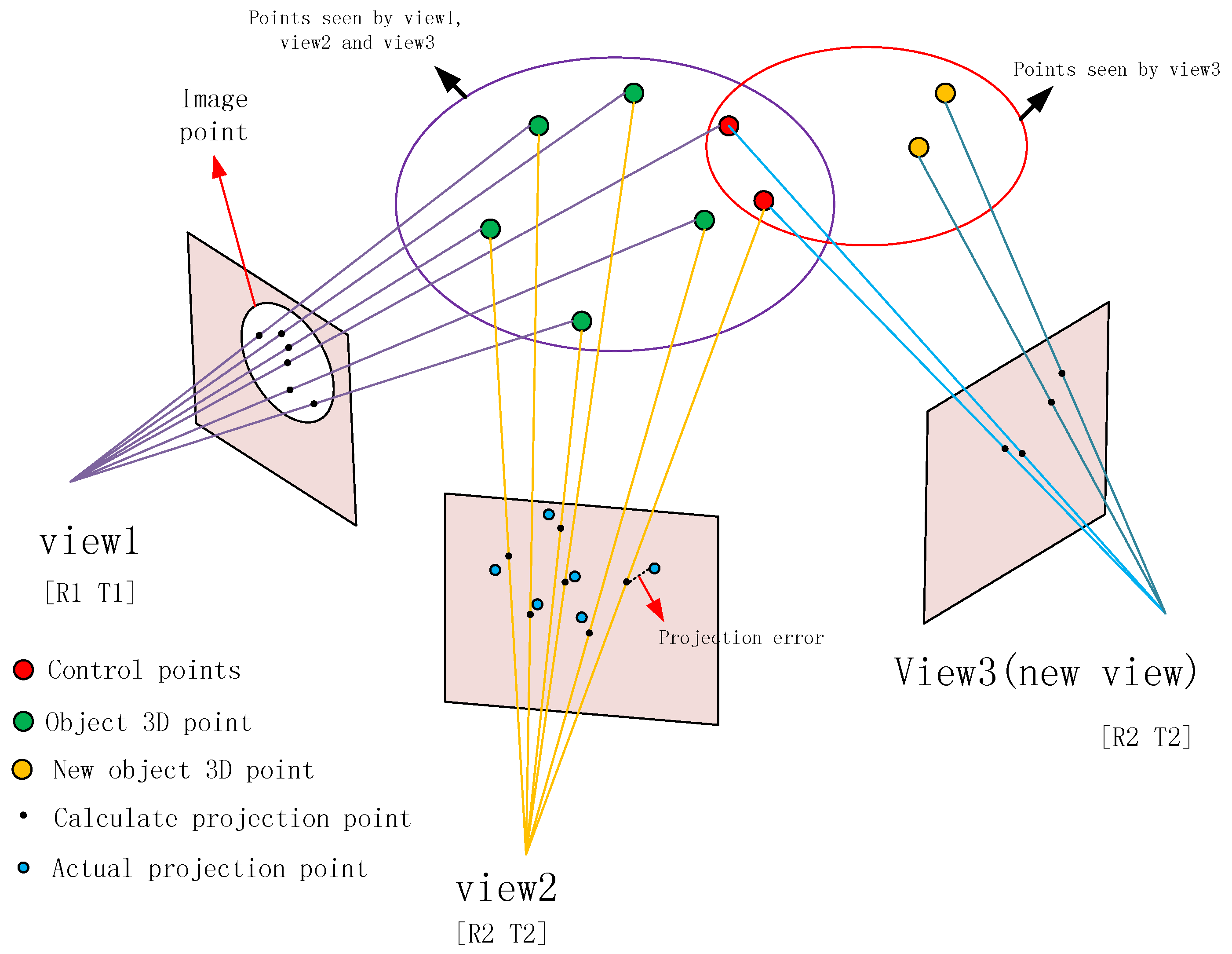
1 | The difference between the weighted bundle adjustment and the bundle adjustment is the weight of the control points’ projection error. The weight is w_j (after an experimental comparison, a value of 20 is suitable for w j ). Equation (9) is the reprojection error formula of the weighted bundle adjustment. |
加权光束法平差和光束法平差的区别在于控制点投影误差的权重,即 w_j(经过对比实验,取值 20 较适合本实验)。公式 (9) 是加权光束法平差的重投影误差公式。
3.3.4. MVS
1 | For the dense reconstruction of the object, considering the characteristics of the problem addressed in this study, we use the method based on depth-map fusion to obtain the dense point cloud. The method is similar to that proposed in [16]. The algorithm first obtains the feature points in the structure calculated by the SfM. By using Delaunay triangulation, we can obtain the mesh data from the 3D feature points. Then, the mesh is used as an outline of the object, which is projected onto the plane of the images to obtain the estimated depth maps. The depth maps are optimized and corrected using the pixel matching algorithm based on the patch. Finally, dense point cloud data can be obtained by fusing these depth maps. |
考虑到本文研究问题的特点,我们准备采用基于深度图融合的方法获取稠密点云。方法与文献 [16] 相似,首先获取由 SfM 计算出的结构中的特征点,通过 Delaunay 三角剖分,我们可以从 3d 特征点获得网格数据。然后将该网格投影到对应的原图上,以获得近似的深度图。之后利用基于分片的像素匹配算法对深度图进行优化和校正,于是我们就可以获得稠密点云。
4. Experiments 实验
4.1. Data Sets
4.2. Precision Evaluation
4.3. Speed Evaluation
4.4. Results
5. Conclusions 结论
References
- Polok, L.; Ila, V.; Solony, M.; Smrz, P.; Zemcik, P. Incremental Block Cholesky Factorization for Nonlinear
Least Squares in Robotics. Robot. Sci. Syst. 2013, 46, 172–178. - Kaess, M.; Johannsson, H.; Roberts, R.; Ila, V.; Leonard, J.J.; Dellaert, F. iSAM2: Incremental smoothing and
mapping using the Bayes tree. Int. J. Robot. Res. 2012, 31, 216–235. [CrossRef] - Liu, M.; Huang, S.; Dissanayake, G.; Wang, H. A convex optimization based approach for pose SLAM
problems. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems,
Vilamoura-Algarve, Portugal, 7–12 October 2012; pp. 1898–1903. - Beardsley, P.A.; Torr, P.H.S.; Zisserman, A. 3D model acquisition from extended image sequences.
In Proceedings of the European Conference on Computer Vision, Cambridge, UK, 14–18 April 1996;
pp. 683–695. - Mohr, R.; Veillon, F.; Quan, L. Relative 3-D reconstruction using multiple uncalibrated images. Int. J.
Robot. Res. 1995, 14, 619–632. [CrossRef] - Dellaert, F.; Seitz, S.M.; Thorpe, C.E.; Thrun, S. Structure from motion without correspondence.
In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Hilton Head Island,
SC, USA, 15 June 2000; Volume 552, pp. 557–564. - Moulon, P.; Monasse, P.; Marlet, R. Adaptive structure from motion with a contrario model estimation.
In Proceedings of the Asian Conference on Computer Vision, Daejeon, Korea, 5–9 November 2012;
pp. 257–270. - Wu, C. Towards linear-time incremental structure from motion. In Proceedings of the International
Conference on 3DTV-Conference, Aberdeen, UK, 29 June–1 July 2013; pp. 127–134. - Gherardi, R.; Farenzena, M.; Fusiello, A. Improving the efficiency of hierarchical structure-and-motion.
In Proceedings of the Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; - Moulon, P.; Monasse, P.; Marlet, R. Global fusion of relative motions for robust, accurate and scalable
structure from motion. In Proceedings of the IEEE International Conference on Computer Vision, Portland,
OR, USA, 23–28 June 2013; pp. 3248–3255. - Crandall, D.J.; Owens, A.; Snavely, N.; Huttenlocher, D.P. SfM with MRFs: Discrete-continuous optimization
for large-scale structure from motion. IEEE Trans. Pattern Anal. Mach. Intell. 2013 , 35, 2841–2853. [CrossRef]
[PubMed] - Sweeney, C.; Sattler, T.; Höllerer, T.; Turk, M. Optimizing the viewing graph for structure-from-motion.
In Proceedings of the IEEE International Conference on Computer Vision, Los Alamitos, CA, USA,
7–13 December 2015; pp. 801–809. - Snavely, N.; Simon, I.; Goesele, M.; Szeliski, R.; Seitz, S.M. Scene reconstruction and visualization from
community photo collections. Proc. IEEE 2010, 98, 1370–1390. [CrossRef] - Wu, C.; Agarwal, S.; Curless, B.; Seitz, S.M. Multicore bundle adjustment. In Proceedings of the Computer
Vision and Pattern Recognition, Colorado Springs, CO, USA, 20–25 June 2011; pp. 3057–3064. - Furukawa, Y.; Ponce, J. Accurate, dense, and robust multiview stereopsis. IEEE Trans. Pattern Anal.
Mach. Intell. 2010, 32, 1362–1376. [CrossRef] [PubMed] - Shen, S. Accurate multiple view 3D reconstruction using patch-based stereo for large-scale scenes. IEEE Trans.
Image Process. 2013, 22, 1901–1914. [CrossRef] [PubMed]
Sensors 2018, 18, 225 20 of 20 - Li, J.; Li, E.; Chen, Y.; Xu, L. Bundled depth-map merging for multi-view stereo. In Proceedings of the
Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 2769–2776. - Schönberger, J.L.; Zheng, E.; Frahm, J.M.; Pollefeys, M. Pixelwise View Selection for Unstructured Multi-View
Stereo; Springer International Publishing: New York, NY, USA, 2016. - Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004 , 60, 91–110.
[CrossRef] - Moulon, P.; Monasse, P. Unordered feature tracking made fast and easy. In Proceedings of the European
Conference on Visual Media Production, London, UK, 5–6 December 2012. - Moisan, L.; Moulon, P.; Monasse, P. Automatic homographic registration of a pair of images, with a contrario
elimination of outliers. Image Process. Line 2012, 2, 329–352. [CrossRef] - Fischler, M.A.; Bolles, R.C. Random sample consensus: A paradigm for model fitting with applications to
image analysis and automated cartography. Read. Comput. Vis. 1987, 24, 726–740. - Zhang, Z. A flexible new technique for camera calibration. IEEE Trans. Pattern Anal. Mach. Intell. 2000 , 22,
1330–1334. [CrossRef] - Hartley, R.; Zisserman, A. Multiple View Geometry in Computer Vision, 2nd ed.; Cambridge University Press:
Cambridge, UK, 2003. - Triggs, B.; Mclauchlan, P.F.; Hartley, R.I.; Fitzgibbon, A.W. Bundle adjustment—A modern synthesis.
In Proceedings of the International Workshop on Vision Algorithms: Theory and Practice, Corfu, Greece,
21–22 September 1999; pp. 298–372. - Ceres Solver. Available online: http://ceres-solver.org (accessed on 14 January 2018).
- Sølund, T.; Buch, A.G.; Krüger, N.; Aanæs, H. A large-scale 3D object recognition dataset. In Proceedings
of the Fourth International Conference on 3D Vision, Stanford, CA, USA, 25–28 October 2016; pp. 73–82.
Available online: http://roboimagedata.compute.dtu.dk (accessed on 14 January 2018). - Jensen, R.; Dahl, A.; Vogiatzis, G.; Tola, E. Large scale multi-view stereopsis evaluation. In Proceedings of
the Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 406–413. - Pierrot Deseilligny, M.; Clery, I. Apero, an Open Source Bundle Adjusment Software for Automatic
Calibration and Orientation of Set of Images. In Proceedings of the ISPRS—International Archives of
the Photogrammetry, Remote Sensing and Spatial Information Sciences XXXVIII-5/W16, Trento, Italy,
2–4 March 2012; pp. 269–276. - Galland, O.; Bertelsen, H.S.; Guldstrand, F.; Girod, L.; Johannessen, R.F.; Bjugger, F.; Burchardt, S.; Mair, K.
Application of open-source photogrammetric software MicMac for monitoring surface deformation in
laboratory models. J. Geophys. Res. Solid Earth 2016, 121, 2852–2872. [CrossRef] - Rupnik, E.; Daakir, M.; Deseilligny, M.P. MicMac—A free, open-source solution for photogrammetry.
Open Geosp. Data Softw. Stand. 2017, 2, 14. [CrossRef] - Cloud Compare. Available online: http://www.cloudcompare.org (accessed on 14 January 2018).